Capítulo 6 Manejo de datos con tidyverse
En esta capítulo brindaremos las pautas de trabajo de uno de los paquetes más importantes para análisis de datos. Esta colección de paquetes ha sido diseñado para facilitar el flujo de trabajo en estadística y análisis de datos. Tareas recurrentes que se realizan con este objetivo son cubiertas por diferentes paquetes de tidyverse: importar datos, reordarlos, transformarlos y manipularlos para que estén listos para el análisis, y visualización. Los paquetes que pertenecen al núcleo de tidyverse se activan en la sesión de RStudio tras ejecutar library(tidyverse). Estos son:
- readr: carga de archivos orientada a producir tibbles.
- dplyr: manipulación, arreglo y ordenamiento de bases de datos.
- ggplot2: reconocida como la mejor librería de graficación estadística.
- tibble: modernización de las capacidades de un data frame.
- tidyr: complemento de dplyr limpieza de datos.
- purrr: trabajo mejorado en programación funcional.
- stringr: trabajo con cadenas de texto de una manera cohesiva y simple.
- forcats: manejo de variables categóricas (factores).
Para más detalles, visita la página web de tidyverse.
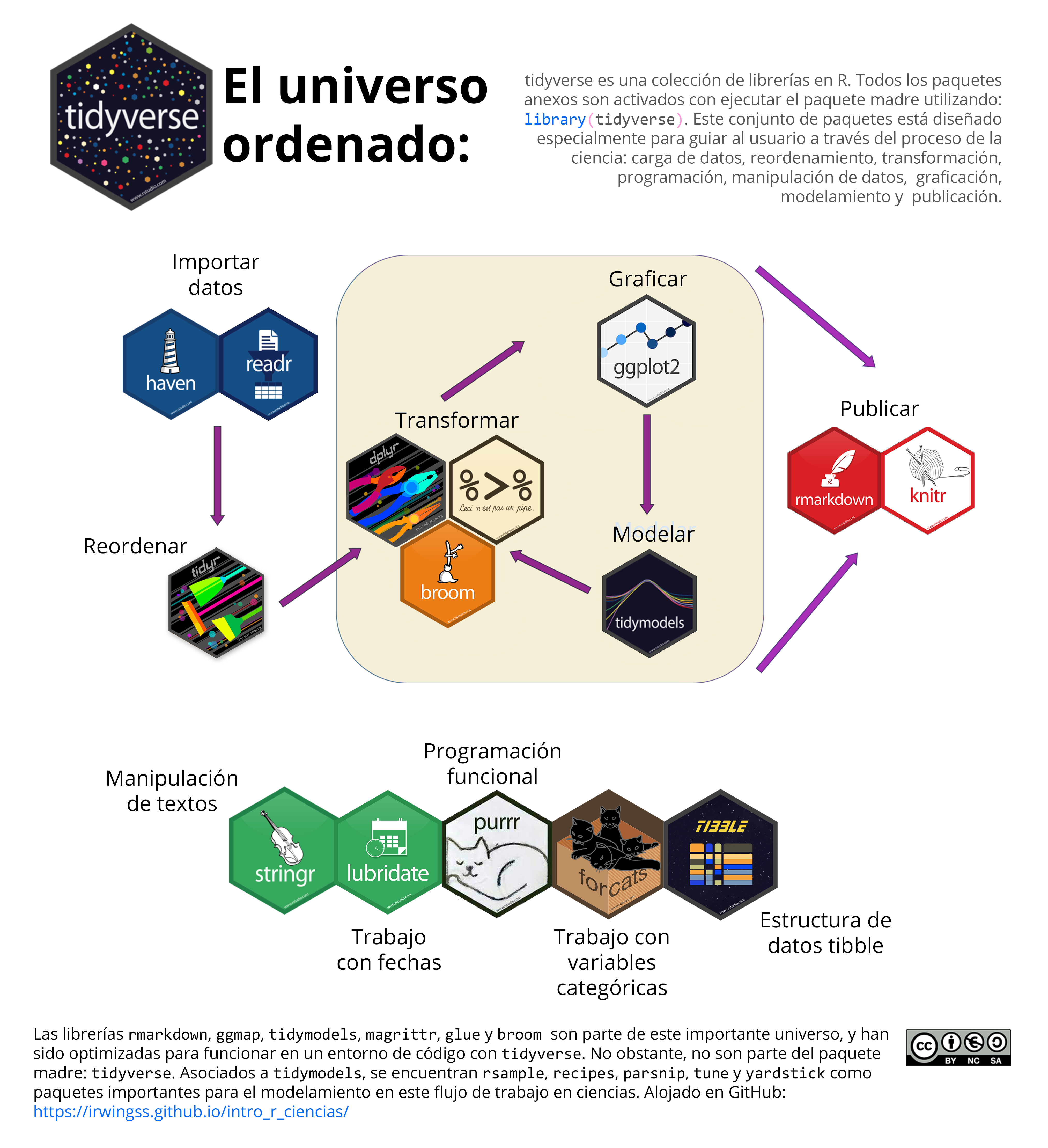
Figura 6.1: Librerías de tidyverse y asociadas. Se ha creado una masiva cantidad de librerías que mejoran las particularidades de tidyverse para ofrecer una experiencia de usuario más completa en diferentes áreas:carga de datos, reordenamiento, transformación, programación, manipulación de datos, graficación, modelamiento y publicación.
Más allá de los ocho paquetes núcleo de tidyverse, se ha desarrollado una gran batería de paquetes asociados, diseñados en el entorno de la sintaxis especial de esta librería. El ecosistema de tidyverse incluye librerías para la carga de bases de datos provenientes de softwares estadísticos (e.g., SPSS con haven), manejo de variables especiales (e.g., datos de fechas con lubridate), modelamiento estadístico (con tidymodels) y revisión de modelos (con broom). Otros paquetes se han desarrollado para cubrir funciones que interactúen en las pipelines (pipe original %>% del paquete magrittr), para crear código más legible (e.g., funciones de rstatix).
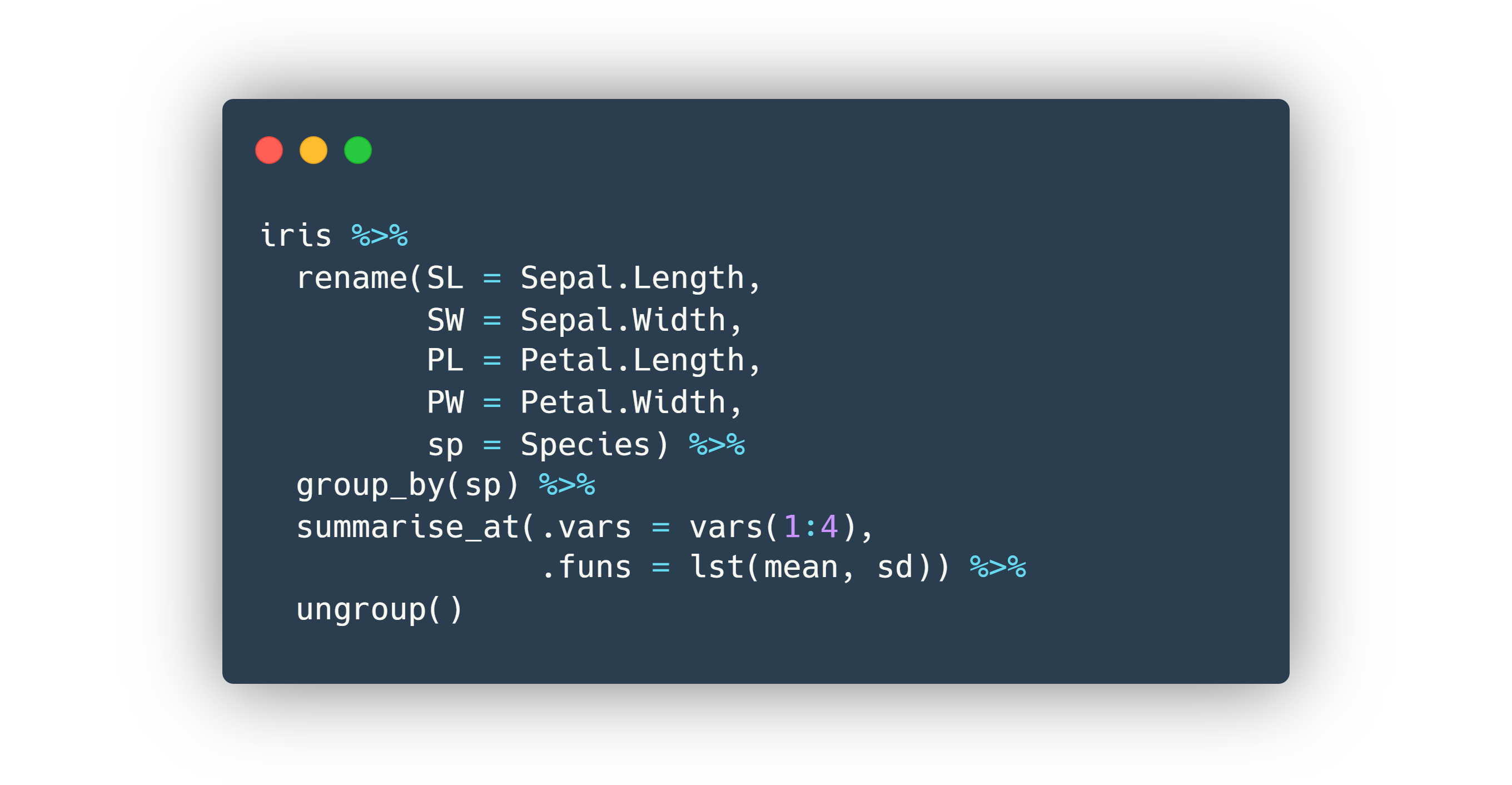
Figura 6.2: Ejemplo del uso de pipe (%>%) en una pipeline para trabajar con tidyverse.
Activación de tidyverse
Para instalar tidyverse en tu equipo, ejecuta:
install.packages("tidyverse")Para activar tidyverse, ejecuta:
library(tidyverse)Resolver conflictos
Tras activar tidyverse, aparecerán en la consola los paquetes nucleo que estan siendo activados (Attaching packages) y los conflictos que tienen con otras librerías (Conflicts) (Figura 6.3). Un conflicto significa que dentro de la librería activada (tidyverse en este caso) existen una o más funciones que tienen el mismo nombre que una función alojada en otra librería actualmente activa en la sesión de RStudio. El texto dplyr::filter() masks stats::filter() indica que la función filter() de la librería dplyr es idéntica en nombre a filter() de la librería stats.
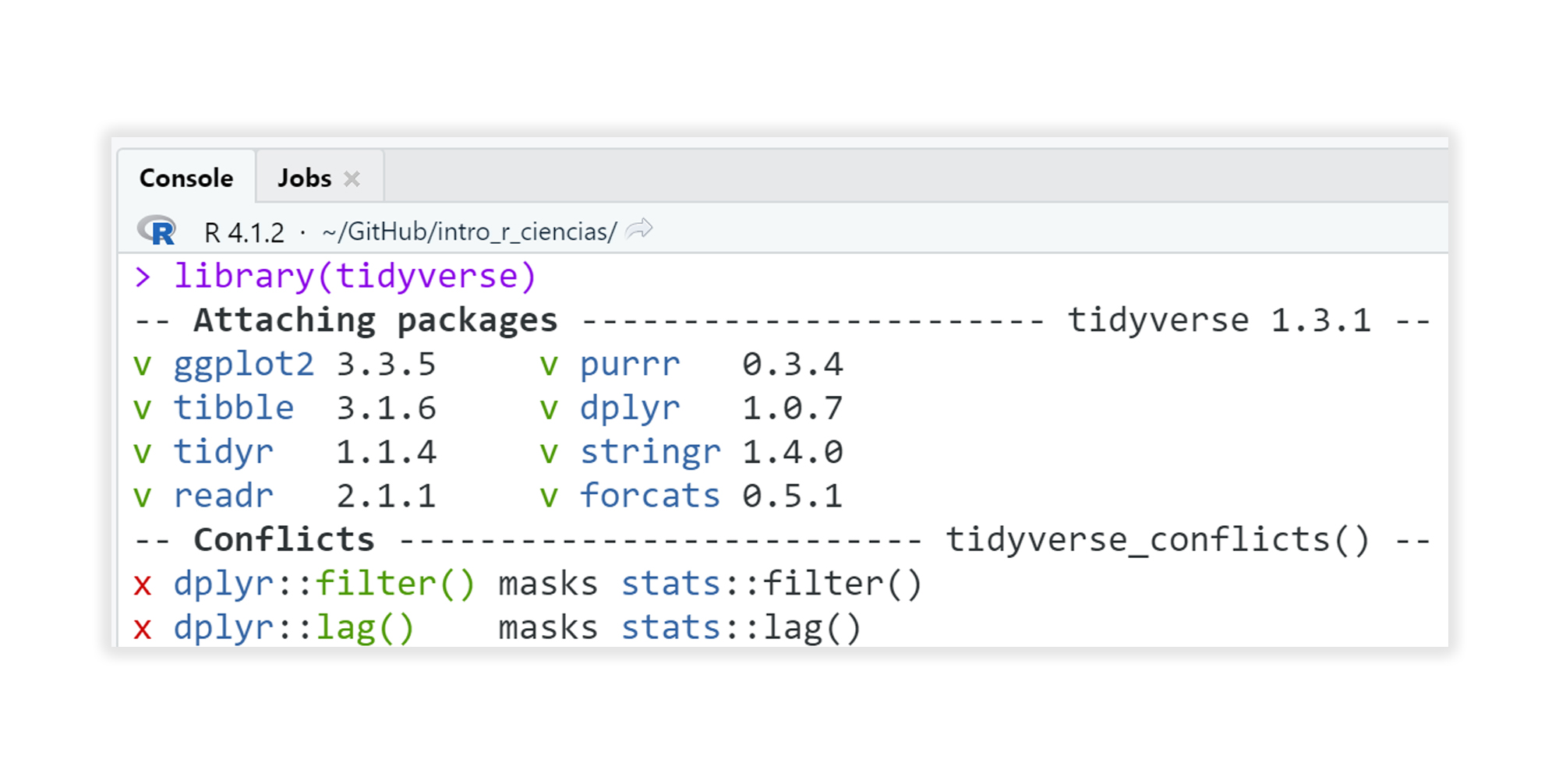
Figura 6.3: Vista previa de los conflictos detectados en consola tras la activación de la librería tidyverse.
Para resolver el conflicto, cada vez que se use una función conflictiva se debe especificar la librería de origen con el operador ::; el código debe ser como el siguiente: dplyr::filter(). R reconocerá que se está utilizando la función filter() del paquete dplyr.