6.4 Tablas anchas y largas con tidyr
En general, mucho de lo que se puede hacer en R necesita de tablas anchas. Este es el nombre que reciben las tablas que cumplen con ser tidy (ordenadas, revisa la Sección 6.1 Datos ordenados):
- cada columna es una variable.
- cada fila es una observación.
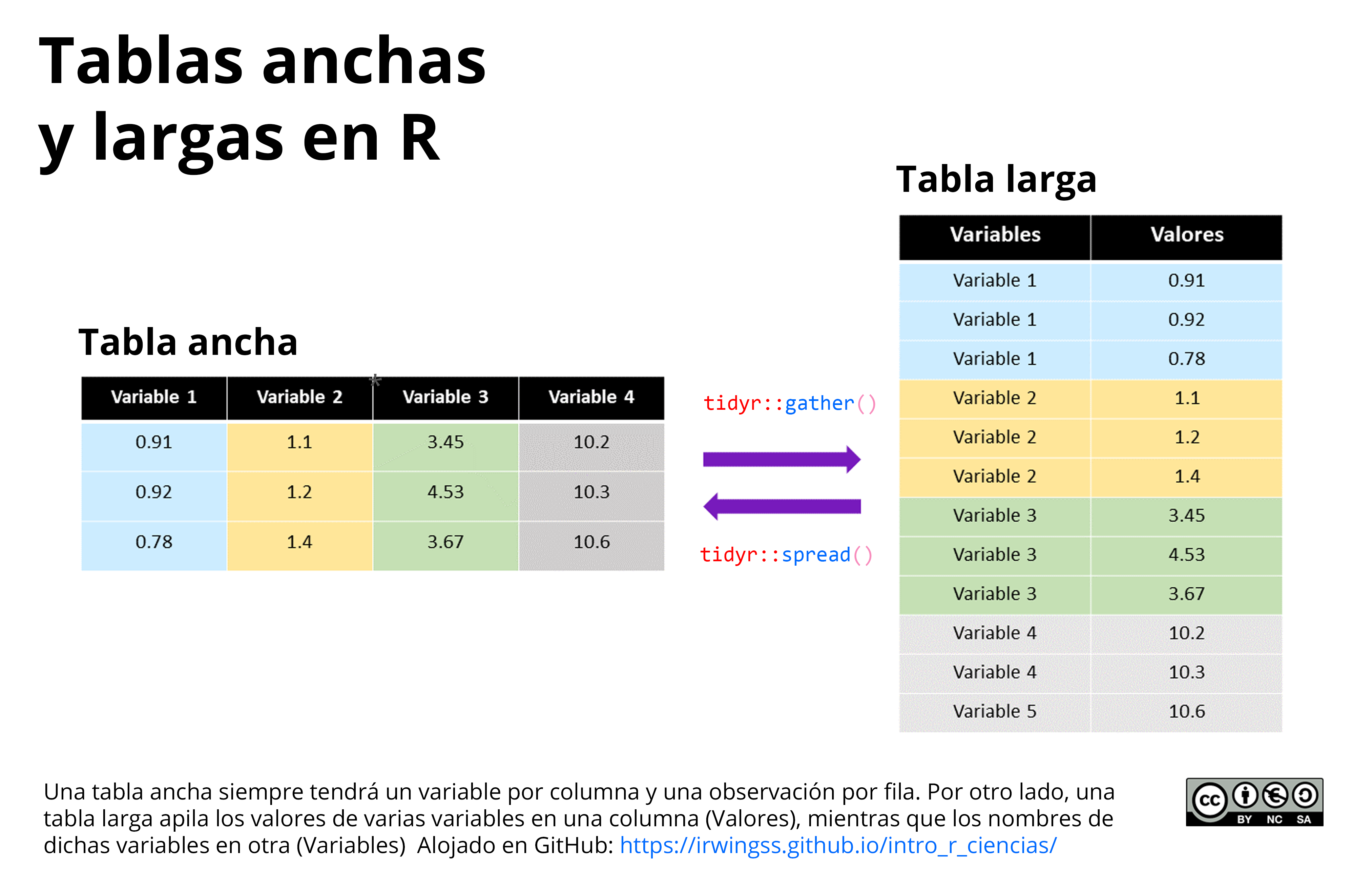
Figura 6.12: Comparativa entre tabla ancha y larga, y las funciones para pasar de una estructura a otra.
6.4.1 De ancha a larga
En ciertas ocasiones, trabajar con tablas largas es lo que necesitamos para analizar o generar gráficos con los datos. La función gather() de la librería tidyr permite convertir una tabla ancha en larga, apilando dos o más variables en tan solo dos columnas: una de etiquetas (argumento key) y una de valores o contenidos de las celdas (argumento value). La estructura básica es:
gather(DF, # base de datos
key = "COL1", # nombre de la futura columna de etiquetas
value = "COL2", # nombre de la futura columna de valores
COL3:COL4) # columnas a apilar (e.g, posiciones 3:4)Ejemplo 6.1 Considera la tabla mice2:
# install.packages("datarium")
library(datarium)
data("mice2")
# Ver el contenido
mice2
# id before after
# 1 1 187.2 429.5
# 2 2 194.2 404.4
# 3 3 231.7 405.6
# 4 4 200.5 397.2
# 5 5 201.7 377.9
# 6 6 235.0 445.8
# 7 7 208.7 408.4
# 8 8 172.4 337.0
# 9 9 184.6 414.3
# 10 10 189.6 380.3mice2 es una tabla ancha. Para apilar sus columnas before y after en una nueva columna llamada Tiempo, mientras que sus valores se apilan en Valores, se tiene:
# Utilizar gather() para apilar las columnas 2 y 3
# en las columnas Tiempo (etiquetas) y Valor (valores)
ratones_larga <- gather(mice2, key="Tiempo", value="Valor", 2:3)
# Ver el contenido
ratones_larga
# id Tiempo Valor
# 1 1 before 187.2
# 2 2 before 194.2
# 3 3 before 231.7
# 4 4 before 200.5
# 5 5 before 201.7
# 6 6 before 235.0
# 7 7 before 208.7
# 8 8 before 172.4
# 9 9 before 184.6
# 10 10 before 189.6
# 11 1 after 429.5
# 12 2 after 404.4
# 13 3 after 405.6
# 14 4 after 397.2
# 15 5 after 377.9
# 16 6 after 445.8
# 17 7 after 408.4
# 18 8 after 337.0
# 19 9 after 414.3
# 20 10 after 380.36.4.2 De larga a ancha
Apilar variables en tablas largas es muy frecuente en procesos de toma de datos, quizá por facilidad o rapidez en el almacenamiento de los mismos durante los estudios. La función spread() permite dispersar datos partiendo de dos columnas: una de etiquetas apiladas (key) y otra de valores apilados (values), hacia las columnas que sean necesarias (igual a la cantidad de niveles en key). La estructura básica es:
spread(DF, # base de datos
key = COL1, # columna de etiquetas
value = COL2) # columna de valoresEjemplo 6.2 Considera la tabla ratones_larga obtenida en el ejemplo anterior:
# Utilizar gather() para apilar las columnas 2 y 3
# en las columnas Tiempo (etiquetas) y Valor (valores)
spread(ratones_larga, key=Tiempo, value=Valor)
# id after before
# 1 1 429.5 187.2
# 2 2 404.4 194.2
# 3 3 405.6 231.7
# 4 4 397.2 200.5
# 5 5 377.9 201.7
# 6 6 445.8 235.0
# 7 7 408.4 208.7
# 8 8 337.0 172.4
# 9 9 414.3 184.6
# 10 10 380.3 189.6