5.2 Control de flujo
En R existen algunos operadores para controlar el flujo de las acciones a tomar en la ejecución. Esto sucede solamente cuando se cumple una condición dada. Recordemos que las condiciones lógicas se resuelven como verdadera TRUE o falsa FALSE. Existen operadores de elección (if, else) y de iteración o loop (for, while). Se revisará a detalle sus usos en las siguientes secciones.
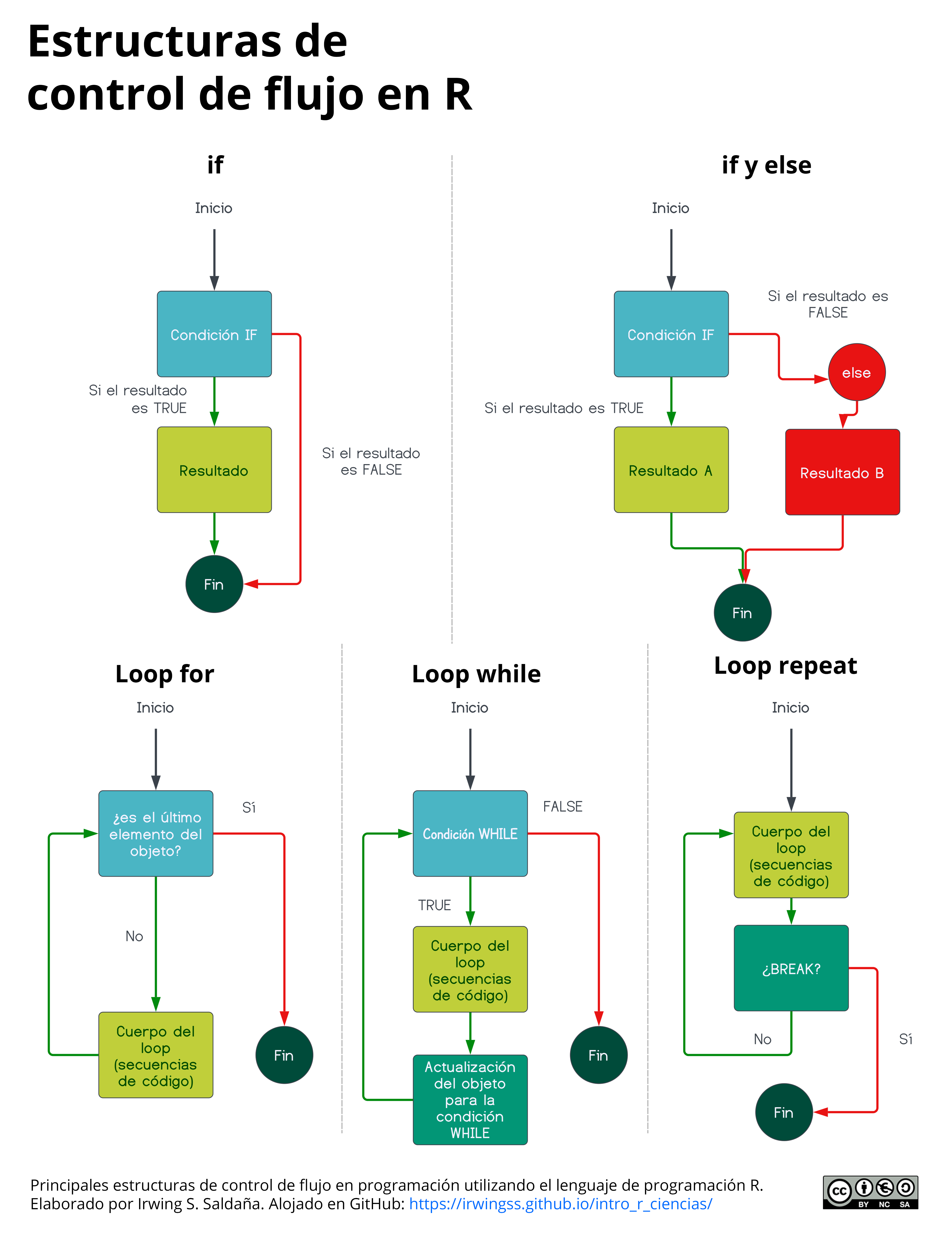
Figura 5.2: Diagramas de flujo para comprender cómo funcionan las principales estructuras de control de flujo en programación con R.
5.2.1 Control con if
El primer operador de control de flujo a destacar es el condicional if. Este significa si, y ejecuta la expresión: si A se cumple (es decir, si A es TRUE), muestro un resultado. Este tienen la estructura básica:
if (condición) acción_si_la_condición_es_verdaderaEjemplo 5.5 Para poner en contexto lo anterior:
### Crear una condición verdadera
condicion <- TRUE
if(condicion) 1
# [1] 1En este sentido,if mostrará como resultado lo que esté a la derecha del paréntesis de condición, siempre y cuando la condición sea verdadera. Cuando la condición es falsa, no muestra resultado alguno:
### Crear una condición falsa
condicion <- FALSE
if (condicion) 1Ejemplo 5.6 En la siguiente expresión, reemplazaremos la condición TRUE por una condición real con un vector llamado num. Se hará la pregunta lógica ¿es el objeto num numeric?. El resultado será un texto indicando que num es un número siempre que la condición sea verdadera.
### Cuando num es un número
num <- 123
if (is.numeric(num)) paste(num, "es un número")
# [1] "123 es un número"
### Cuando num no es un número
num <- "Andes Tropicales"
if (is.numeric(num)) paste(num, "es un número")En el ejemplo con "Andes Tropicales", la condición no fue verdadera, if no mostró resultado alguno en consola.
5.2.2 Control completo con if y else
El segundo operador de control que uno debe conocer es else. Este significa entonces, y suele colocarse acompañando a if para completar la condición universal: si A se cumple, muestro un resultado; si A no se cumple, entonces muestro otro resultado. Utilizando ambis, se obtiene tienen la estructura básica:
if (condición) acción_si_la_condición_es_verdadera else acción_si_la_condición_es_falsaEjemplo 5.7 Poniendo en contexto lo mencionado:
### Usar if y else con una condición lógica
condicion <- TRUE
if (condicion) 1 else 0
# [1] 1
### Usar if y else con una condición lógica
condicion <- FALSE
if (condicion) 1 else 0
# [1] 0Es más frecuente utilizar llaves {} para definir el resultado de if o el otro resultado de else:
### Usar if y else con una condición lógica
condicion <- TRUE
if (condicion) {1} else {0}
# [1] 1
### Usar if y else con una condición lógica
condicion <- FALSE
if (condicion) {1} else {0}
# [1] 0Para escribir un código con varias líneas de if y else, es necesario respetar el sangrado (espacio desde el borde), siendo que else se muestre sangrado dentro de la cadena de código iniciada con if.
### Código de if y else en varias líneas
condicion <- FALSE
if (condicion) {
1
} else {
0}
# [1] 0Ejemplo 5.8 Veamos una aplicación más completa de todo lo discutido hasta el momento:
### Cuando num es un número
num <- 123
if (is.numeric(num)) {
paste(num, "es un número")
} else {
paste(num, "no es un número")
}
# [1] "123 es un número"
### Cuando num no es un número
num <- "Andes Tropicales"
if (is.numeric(num)) {
paste(num, "es un número")
} else {
paste(num, "no es un número")
}
# [1] "Andes Tropicales no es un número"Ejemplo 5.9 A continuación varias aplicaciones para identificar si un valor numérico es par o impar, para identificar si un valor es NA, y para identificar si un valor es del tipo carácter o texto:
### Con valor numérico para identificar par o impar
valor <- 120
if((valor %% 2) == 0) {
print(paste(valor,"es par"))
} else if ((valor %% 2) != 0) {
print(paste(valor,"es impar"))
}
# [1] "120 es par"
### Con valor NA para identificar si es NA o un texto
valor <- NA
if (is.na(valor)) {
print(paste(valor, "es un valor perdido"))
} else {
print(paste(valor, "no es un valor perdido, debe ser un texto"))
}
# [1] "NA es un valor perdido"
### Con valor NA para identificar si es NA o un texto
valor <- "América"
if (is.na(valor)) {
print(paste(valor, "es un valor perdido"))
} else {
print(paste(valor, "no es un valor perdido, debe ser un texto"))
}
# [1] "América no es un valor perdido, debe ser un texto"Ejemplo 5.10 Crear un proceso complejo que involucre una respuesta para cualquiera de los tipos de elementos ofrecidos en el ejemplo anterior (valor numérico, NA y textual) puede ser un dolor de cabeza. Si se concatenan las condiciones con else e if de manera errada, generará un error:
### Forma errada
valor <- "Mil quinientos veinte"
if((valor %% 2) == 0) {
print(paste(valor,"es par"))
} else if ((valor %% 2) != 0) {
print(paste(valor,"es impar"))
} else if (is.na(valor)) {
print(paste(valor, "es un valor perdido"))
} else {
print(paste(valor, "no es un valor perdido, debe ser un texto"))
}
# Error in valor%%2 : non-numeric argument to binary operatorLa manera correcta de crear esta condición compleja se obtiene primero preguntando si el elemento valor es número o no. Este paso es fundamental debido a las limitaciones razonables de operar numéricamente con %% un texto, generando un error:
"Mil quinientos veinte" %% 2
# Error in "Texto"%%2 : non-numeric argument to binary operatorIncluyendo la pregunta ¿es verdad TRUE que el valor es un número? con is.numeric(valor) == TRUE para cuando valor es número; y la pregunta ¿es falso FALSE que el valor es un número? con is.numeric(valor) == FALSE, para cuando valor es texto:
### Tómate el tiempo que necesites para
### entender cómo funciona esta estructura
### Prueba su aplicación cambiando el contenido de valor:
valor <- "Mil quinientos veinte"
if (is.numeric(valor) == TRUE) {
if((valor %% 2) == 0) {
print(paste(valor,"es par"))
} else if ((valor %% 2) != 0) {
print(paste(valor,"es impar"))
}
} else if (is.numeric(valor) == FALSE) {
if (is.na(valor)) {
print(paste(valor, "es un valor perdido"))
} else {
print(paste(valor, "no es un valor perdido, debe ser un texto"))
}
}
# [1] "Mil quinientos veinte no es un valor perdido, debe ser un texto"if como else permiten evaluar elementos dentro de una función y pueden funcionar como interruptores que de decanten en la elección de una ruta de análisis en relación a una condición relacionada con el elemento u objeto de entrada.
Para entender la importancia de estos interruptores en la creación de funciones, revisemos el contenido de la función dist(), que calcula una matriz de distancias para análisis multivariados. Para esta función, es importante especificar qué método de cálculo de distancias se debe usar. Siempre existirá alguno definido por defecto, en este caso "euclidean" (distancia euclidiana). Reconoce las estructuras if y else que usa la función para decidir qué hacer cuando se le a otorgado uno u otro valor en el argumento method.
dist
# function (x, method = "euclidean", diag = FALSE, upper = FALSE,
# p = 2)
# {
# if (!is.na(pmatch(method, "euclidian")))
# method <- "euclidean"
# METHODS <- c("euclidean", "maximum", "manhattan", "canberra",
# "binary", "minkowski")
# method <- pmatch(method, METHODS)
# if (is.na(method))
# stop("invalid distance method")
# if (method == -1)
# stop("ambiguous distance method")
# x <- as.matrix(x)
# N <- nrow(x)
# attrs <- if (method == 6L)
# list(Size = N, Labels = dimnames(x)[[1L]], Diag = diag,
# Upper = upper, method = METHODS[method], p = p, call = match.call(),
# class = "dist")
# else list(Size = N, Labels = dimnames(x)[[1L]], Diag = diag,
# Upper = upper, method = METHODS[method], call = match.call(),
# class = "dist")
# .Call(C_Cdist, x, method, attrs, p)
# }
# <bytecode: 0x000001451075c7c0>
# <environment: namespace:stats>5.2.3 Condicionales en vectores de más de un elemento con ifelse()
De manera similar al uso de if y else, es posible operar de manera vectorial. Esto significa: aplicar una condición a cada elemento de un vector, para que cuando esta se cumpla (sea TRUE) se de un resultado, mientras que otorgue otro cuando no se cumpla (sea FALSE). La función ifelse(), encargada de ello, requiere como argumentos una condición lógica, un valor para cuando la condición sea TRUE y otro valor para cuando sea FALSE. La estructura básica es:
ifelse(condicion, "acción_si_la_condición_es_verdadera", "acción_si_la_condición_es_falsa")Ejemplo 5.11 Usando ifelse() para identificar los valores pares e impares de un vector numérico:
### Crear un vector cualquiera
vector <- 1:50
### Usar ifelse()
ifelse((vector %% 2) == 0, "Par", "Impar")
# [1] "Impar" "Par" "Impar" "Par" "Impar" "Par" "Impar" "Par" "Impar" "Par"
# [11] "Impar" "Par" "Impar" "Par" "Impar" "Par" "Impar" "Par" "Impar" "Par"
# [21] "Impar" "Par" "Impar" "Par" "Impar" "Par" "Impar" "Par" "Impar" "Par"
# [31] "Impar" "Par" "Impar" "Par" "Impar" "Par" "Impar" "Par" "Impar" "Par"
# [41] "Impar" "Par" "Impar" "Par" "Impar" "Par" "Impar" "Par" "Impar" "Par"Es posible incluir una función ifelse() dentro de otra en la posición de resultado FALSE para concatenar varias condiciones aplicadas al mismo vector:
### Usar ifelse()
ifelse((vector %% 2) == 0 & vector > 10, "Par >10",
ifelse((vector %% 2) == 0 & vector <= 10, "Par <=10",
ifelse((vector %% 2) != 0 & vector > 10, "impar >10", "impar <=10")))
# [1] "impar <=10" "Par <=10" "impar <=10" "Par <=10" "impar <=10" "Par <=10"
# [7] "impar <=10" "Par <=10" "impar <=10" "Par <=10" "impar >10" "Par >10"
# [13] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [19] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [25] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [31] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [37] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [43] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [49] "impar >10" "Par >10"5.2.4 Condicionales en vectores case_when() de dplyr
La función case_when() de la librería dplyr es la solución para cuando se necesita utilizar muchos ifelse() concatenados. Su uso, como otras funciones de dplyr, es sencillo. La estructura básica es:
case_when(
condicion ~ "resultado_verdadero",
condicion ~ "resultado_verdadero",
condicion ~ "resultado_verdadero",
condicion ~ "resultado_verdadero"
)Ejemplo 5.12 Resolviendo el último ejemplo de la sección anterior con case_when():
### Crear un vector
vector <- 1:50
### Evaluar el vector con case_when()
library(dplyr)
case_when(
(vector %% 2) == 0 & vector > 10 ~ "Par >10",
(vector %% 2) == 0 & vector <= 10 ~ "Par <=10",
(vector %% 2) != 0 & vector > 10 ~ "impar >10",
(vector %% 2) != 0 & vector <= 10 ~ "impar <=10"
)
# [1] "impar <=10" "Par <=10" "impar <=10" "Par <=10" "impar <=10" "Par <=10"
# [7] "impar <=10" "Par <=10" "impar <=10" "Par <=10" "impar >10" "Par >10"
# [13] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [19] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [25] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [31] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [37] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [43] "impar >10" "Par >10" "impar >10" "Par >10" "impar >10" "Par >10"
# [49] "impar >10" "Par >10"Cuando hay elementos que no cumplen con ninguna condición ofrecida, el elemento se reemplaza por NA en el vector de resultado:
### Crear un vector
vector <- 1:50
### Evaluar el vector con case_when()
### con una sola condición
library(dplyr)
case_when(
(vector %% 2) == 0 & vector > 10 ~ "Par >10"
)
# [1] NA NA NA NA NA NA NA NA
# [9] NA NA NA "Par >10" NA "Par >10" NA "Par >10"
# [17] NA "Par >10" NA "Par >10" NA "Par >10" NA "Par >10"
# [25] NA "Par >10" NA "Par >10" NA "Par >10" NA "Par >10"
# [33] NA "Par >10" NA "Par >10" NA "Par >10" NA "Par >10"
# [41] NA "Par >10" NA "Par >10" NA "Par >10" NA "Par >10"
# [49] NA "Par >10"5.2.5 Ciclos o Loops con for
El segundo grupo de operadores de control de flujo incluye a los responsables de ciclos, iteraciones o loops. Un loop con for tienen la siguiente estructura básica:
for (elemento in vector_secuencial) {acciones a realizar}5.2.5.1 Entendiendo la estructura básica de for
Elemento y vector_secuencial son dos cosas que no se han visto hasta el momento. Elemento se comporta como una variable de posición. Es clásico que se coloque a i como elemento, pero puede ser cualquier letra o palabra, siempre y cuando esta se utilice dentro del loop. El elemento funciona como variable de posición, y en cada vuelta del loop, i será reemplazado con un elemento del vector_secuencial, uno a uno en orden correlativo.
El vector_secuencial, por su parte, es un vector que debe contener la secuencia correlativa de números que vaya desde 1 hasta la cantidad máxima de elementos que tiene el vector sobre el que se pretende aplicar el loop. Si el vector inicial al que se le aplicará el loop contiene solo cuatro elementos: c(10.1, 50.9, 23.4, 31.5), se debe colocar una de las siguientes opciones dentro del paréntesis de for:
### Vector sobre el que aplicar el loop
vector <- c(10.1, 50.9, 23.4, 31.5)### Opción 1: colocar un rango manualmente (poco eficiente)
for (i in 1:4)
### Opción 1: colocar un rango con length() (no recomendado)
for (i in 1:length(vector))
### Opción 1: usando seq_along() para crear el rango (recomendado)
for (i in seq_along(vector))5.2.5.2 Uso de for
Ejemplo 5.13 Utilizando un loop para obtener solo los valores mayores igual al promedio de un conjunto de datos:
### Crear aleatoriamente un conjunto de datos
### que siga la distribución normal
set.seed(123)
aleatorio <- rnorm(200, mean = 20, sd=5.6)
### Crear un objeto vacío para rellenarlo
### con el resultado de cada vuelta del loop
res <- c()
### Loop sin importar que se generen NA
for (i in seq_along(aleatorio)){
if (aleatorio[i] >= mean(aleatorio)) {
res[i] <- aleatorio[i]
}
}
### Resultado
res
# [1] NA NA 28.73 20.39 20.72 29.60 22.58 NA NA NA 26.85 22.01 22.24
# [14] 20.62 NA 30.01 22.79 NA 23.93 NA NA NA NA NA NA NA
# [27] 24.69 20.86 NA 27.02 22.39 NA 25.01 24.92 24.60 23.86 23.10 NA NA
# [40] NA NA NA NA 32.15 26.76 NA NA NA 24.37 NA 21.42 NA
# [53] NA 27.66 NA 28.49 NA 23.27 20.69 21.21 22.13 NA NA NA NA
# [66] 21.70 22.51 20.30 25.16 31.48 NA NA 25.63 NA NA 25.74 NA NA
# [79] 21.02 NA 20.03 22.16 NA 23.61 NA 21.86 26.14 22.44 NA 26.43 25.56
# [92] 23.07 21.34 NA 27.62 NA 32.25 28.58 NA NA NA 21.44 NA NA
# [105] NA NA NA NA NA 25.15 NA 23.40 NA NA 22.91 21.69 20.59
# [118] NA NA NA 20.66 NA NA NA 30.33 NA 21.32 20.44 NA NA
# [131] 28.09 22.53 20.23 NA NA 26.34 NA 24.14 30.69 NA 23.93 NA NA
# [144] NA NA NA NA 23.85 31.76 NA 24.41 24.31 21.86 NA NA NA
# [157] 23.15 NA 25.47 NA 25.90 NA NA 38.15 NA 21.67 23.56 NA 22.89
# [170] 22.07 NA 20.37 NA 31.92 NA NA 20.21 21.74 22.44 NA NA 27.07
# [183] NA NA NA NA 26.22 20.47 24.22 NA 21.20 NA 20.53 NA NA
# [196] 31.18 23.36Para no generar NA en el resultado se usa un truco: ir adicionando el resultado a res como un vector que concatena el contenido de hasta la iteración anterior de res, más el contenido de la iteración actual:
### Loop sin NA
res <- c()
for (i in seq_along(aleatorio)){
if (aleatorio[i] >= mean(aleatorio)) {
res <- c(res, aleatorio[i]) # aquí está el truco
}
}
### Resultado
res
# [1] 28.73 20.39 20.72 29.60 22.58 26.85 22.01 22.24 20.62 30.01 22.79 23.93 24.69
# [14] 20.86 27.02 22.39 25.01 24.92 24.60 23.86 23.10 32.15 26.76 24.37 21.42 27.66
# [27] 28.49 23.27 20.69 21.21 22.13 21.70 22.51 20.30 25.16 31.48 25.63 25.74 21.02
# [40] 20.03 22.16 23.61 21.86 26.14 22.44 26.43 25.56 23.07 21.34 27.62 32.25 28.58
# [53] 21.44 25.15 23.40 22.91 21.69 20.59 20.66 30.33 21.32 20.44 28.09 22.53 20.23
# [66] 26.34 24.14 30.69 23.93 23.85 31.76 24.41 24.31 21.86 23.15 25.47 25.90 38.15
# [79] 21.67 23.56 22.89 22.07 20.37 31.92 20.21 21.74 22.44 27.07 26.22 20.47 24.22
# [92] 21.20 20.53 31.18 23.36Ejemplo 5.14 Otra manera de conseguir el efecto visto en el ejemplo anterio es utilizando el operador condicional next. Este “salta” un ciclo cuando se cumple la condición del if previo. Nota como la condición en if pide lo contrario a lo que se necesita, para que cuando se cumpla se active next y cuando no se cumpla se guarda el valor concatenado en res.
### Crear un objeto vacío
res <- c()
### Loop con next y condición if inversa a lo requerido
for (i in seq_along(aleatorio)){
if (aleatorio[i] < mean(aleatorio)) # condición inversa para usar next
next
res <- c(res, aleatorio[i])
}
### Resultado
res
# [1] 28.73 20.39 20.72 29.60 22.58 26.85 22.01 22.24 20.62 30.01 22.79 23.93 24.69
# [14] 20.86 27.02 22.39 25.01 24.92 24.60 23.86 23.10 32.15 26.76 24.37 21.42 27.66
# [27] 28.49 23.27 20.69 21.21 22.13 21.70 22.51 20.30 25.16 31.48 25.63 25.74 21.02
# [40] 20.03 22.16 23.61 21.86 26.14 22.44 26.43 25.56 23.07 21.34 27.62 32.25 28.58
# [53] 21.44 25.15 23.40 22.91 21.69 20.59 20.66 30.33 21.32 20.44 28.09 22.53 20.23
# [66] 26.34 24.14 30.69 23.93 23.85 31.76 24.41 24.31 21.86 23.15 25.47 25.90 38.15
# [79] 21.67 23.56 22.89 22.07 20.37 31.92 20.21 21.74 22.44 27.07 26.22 20.47 24.22
# [92] 21.20 20.53 31.18 23.36Ejemplo 5.15 Si es requerido frenar el loop antes de que culmine, en base a una nueva condición definida, se debe utilizar break. En nuestro ejemplo, para frenar el loop cuando aparezca el primer valor mayor a 30.5, es necesario ir evaluando en cada iteración del loop si existe al menos un valor > 30.5 en el objeto res. Esto se obtiene con any(res > 30.5). En el momento que se cumpla, break frena el loop.
### Crear un objeto vacío
res <- c()
### Loop con next y condición if inversa a lo requerido
for (i in seq_along(aleatorio)){
if (aleatorio[i] < mean(aleatorio))
next
res <- c(res, aleatorio[i])
if (any(res > 30.5)) # hay que evaluar si hay algún (any)
break
}
### Resultado
res
# [1] 28.73 20.39 20.72 29.60 22.58 26.85 22.01 22.24 20.62 30.01 22.79 23.93 24.69
# [14] 20.86 27.02 22.39 25.01 24.92 24.60 23.86 23.10 32.155.2.6 Ciclos o loops con replicate()
La función replicate() facilita mucho procesos iterativos para simulación. Permite replicar una o varias líneas de código las veces que sean definidas, para almacenarlas como una lista de vectores (con el argumento simplify = FALSE), o como un vector único (con el argumento simplify = TRUE, como está por defecto). Ejemplificaremos su uso con un caso de estudio:
Ejemplo 5.16 Se ha evaluado una población, de la cual se obtuvo como muestra 100 medidas de una longitud. Al obtener el valor más grande de dicha muestra se obtiene:
### Valores del estudio
muestra <- c(155.62, 158.5, 174.06, 161.11, 161.62, 175.42, 164.51, 149.49,
154.52, 156.62, 171.15, 163.63, 163.99, 161.46, 155.66, 176.05,
164.83, 143.39, 166.6, 156.39, 151.21, 158.6, 151.57, 154.16,
155.06, 145.83, 167.79, 161.83, 150.6, 171.41, 164.21, 157.93,
168.29, 168.14, 167.65, 166.49, 165.32, 159.96, 157.84, 157.19,
154.46, 158.69, 149.49, 179.37, 171.01, 150.73, 156.99, 156.44,
167.29, 159.77, 162.7, 160.25, 160.13, 172.41, 158.54, 173.69,
147.03, 165.59, 161.58, 162.38, 163.8, 156.13, 157.6, 151.64,
151.18, 163.14, 164.4, 160.96, 168.52, 178.34, 156.23, 140.41,
169.25, 154.33, 154.51, 169.42, 158.02, 149.88, 162.08, 159.29,
160.55, 163.85, 157.28, 166.11, 158.58, 163.39, 170.04, 164.29,
157.66, 170.49, 169.14, 165.27, 162.58, 155.04, 172.34, 155.28,
179.53, 173.83, 158.45, 151.57)
### El valor más alto de dicha población
max(muestra)
# [1] 179.5Pero ¿Siempre será así?. ¿Será que si evaluo nuevamente la población obtendré el mismo valor máximo?. Como no tenemos dinero ni tiempo para volver a evaluar dicha población, decidimos simularla. En este paso necesitamos información de la muestra:
### Promedio
promedio <- mean(muestra)
### Desviación estándar
desvest <- sd(muestra)Con estos datos se puede simular una población en R. Asumiendo que esta siguen una distribución normal, utilizamos:
### Simular los datos
set.seed(123)
muestra_simulada <- rnorm(100, mean = promedio, sd = desvest)
### Ver los resultados
muestra_simulada
# [1] 156.8 159.5 173.7 161.8 162.3 174.9 164.9 151.2 155.8 157.7 171.0 164.1 164.5
# [14] 162.2 156.9 175.5 165.2 145.7 166.9 157.5 152.8 159.6 153.1 155.5 156.3 147.9
# [27] 167.9 162.5 152.2 171.2 164.7 158.9 168.4 168.3 167.8 166.8 165.7 160.8 158.9
# [40] 158.3 155.8 159.6 151.2 178.5 170.9 152.4 158.1 157.6 167.5 160.6 163.3 161.1
# [53] 160.9 172.2 159.5 173.3 149.0 165.9 162.3 163.0 164.3 157.3 158.6 153.2 152.8
# [66] 163.7 164.8 161.7 168.6 177.6 157.4 142.9 169.3 155.7 155.8 169.4 159.0 151.6
# [79] 162.7 160.2 161.3 164.3 158.3 166.4 159.5 163.9 170.0 164.7 158.7 170.4 169.2
# [92] 165.6 163.2 156.3 172.1 156.5 178.7 173.5 159.4 153.1Para repetir esta simulación diez mil veces, y obtener estadísticos descriptivos de los valores máximos de dichas muchas simuladas, utilizaremos replicate() con dos pasos internos por cada iteración del loop:
- Crear un conjunto de números aleatorios para la iteración.
- Hallar el valor máximo de la longitud en dicho conjunto.
### Usar replicate()
set.seed(123)
resultados <- replicate(n = 10000, {
parcial <- rnorm(100, mean = promedio, sd = desvest)
max(parcial)
}
)
### Revisar el valor máximo, mínimo y promedio de longitudes
### máximas obtenidas por el loop de replicate()
min(resultados)
# [1] 171.8
max(resultados)
# [1] 199.8
mean(resultados)
# [1] 181.2
### Valor máximo de la muestra original
max(muestra)
# [1] 179.5Con ello nos hemos dado cuenta que, asumiendo que la variable tiene distribución de probabilidades normal, el valor máximo de la muestra original (179.53), es menor al promedio poblacional simulado con diez mil réplicas (199.809). Por el contrario, está más cerca del valor máximo más pequeño dentro de los diez mil datos (171.7636).
5.2.7 Ciclos o Loops con while
Otro operador de control de flujo con el que se crea loops es while. A diferencia de for, que opera hasta que se acaben las iteraciones definidas por el rango 1:n, while se detendrá solo hasta que se cumpla una condición. Si dicha condición nunca se cumple, se crea un loop infinito. Un loop con while tienen la siguiente estructura básica:
# Posición inicial
index <- 1
# Loop con while
while (condicion_respecto_a_index) {
acciones a realizar
index <- index + 1
}Es la segunda línea de la condición a realizar dentro del loop while lo que le da la continuidad. En alguna iteración, el ir “sumando” valores al index hará que se cumpla la condición definida.
Ejemplo 5.17 Veamos su aplicación:
# Posición inicial
index <- 1
# Loop con while
while (index <= 5) {
# Acción a realizar
print(paste("El número es", index))
# Suma una posición para la siguiente iteración
index <- index + 1
}
# [1] "El número es 1"
# [1] "El número es 2"
# [1] "El número es 3"
# [1] "El número es 4"
# [1] "El número es 5"Una segunda manera de operar es indicar que se frene el loop hasta que una condición lógica cambie de estado (FALSE a TRUE, o viceversa).
Ejemplo 5.18 Se aplicará el imprimir la secuencia de bases nitrogenadas (letras A, C, G, T) hasta que se ubique la primera base G. Trata de interpretar cada paso dentro de una iteración del loop while:
### Vector sobre el cual hacer la impresión de elementos
vector <- c("A","T","C","A","T","G","G","G","G","C","C")
### Condición en estado falso
condicion <- FALSE
### Índice
index <- 1
### Loop con while
### Aquí !condicion significa:
### "mientras que condición no sea verdadera, continuar"
while ( !condicion ) {
print(vector[index]) # imprime el elemento
index <- index + 1 # adiciona una posición
condicion <- vector[index] == "G" # evalúa si es G la siguiente posición
}
# [1] "A"
# [1] "T"
# [1] "C"
# [1] "A"
# [1] "T"Intentar con for lo explicado en el ejemplo anterior llevaría al resultado erróneo de imprimir todo menos los elementos que se soliciten, como “G”:
### Vector sobre el cual hacer la impresión de elementos
vector <- c("A","T","C","A","G","T","C","A",
"T","G","G","C","G","G","C","C")
### Loop con for
for(i in seq_along(vector)){
if(vector[i]!="G")
print(vector[i])
}
# [1] "A"
# [1] "T"
# [1] "C"
# [1] "A"
# [1] "T"
# [1] "C"
# [1] "A"
# [1] "T"
# [1] "C"
# [1] "C"
# [1] "C"Algo más interesante para el loop while podría ser frenar la impresión de elementos cuando se identifique que a partir de la siguiente iteración aparecerá una secuencia definida.
Ejemplo 5.19 Imagina que necesitas frenar la impresión hasta que aparezca la primera secuencia TGC, en ese orden:
# Objetos necesarios
vector <- c("A","T","C","A","G","T","C","A",
"T","G","G","C","G","G","C","C")
condicion <- FALSE
index <- 1
### Loop con while
while ( !condicion ) {
print(vector[index])
index <- index + 1
condicion <- identical(c(vector[index], vector[index+1],
vector[index+2]), c("T","G","G"))
}
# [1] "A"
# [1] "T"
# [1] "C"
# [1] "A"
# [1] "G"
# [1] "T"
# [1] "C"
# [1] "A"